

사이버보안 AI·빅데이터 챌린지 2023 / CyberSecurity AI BigData Challenge 2023
•
 대상 / 과학기술정보통신장관상
대상 / 과학기술정보통신장관상•
주최 : 과학기술정보통신부
•
주관 : KISA(한국인터넷진흥원)
•
참여트랙 : A트랙 (AI기반 네트워크 웹 공격 분류)
과학기술정보통신부에서 주최하고 KISA(한국인터넷진흥원)에서 주관한 대회로 AI를 활용한 사이버 위협 대응을 위한 대회다.
최근 AI 공부를 시작한터라 배움을 목적으로 참가했고 지인 중에서도 AI를 잘하는 친구와 함께 대회를 나가게 됐다. 대회 준비 초기에는 부족해 많이 쫓아갔지만 대회 막바지에 제안한 모델 개선 방안이 실제로 성능을 올리는 등 딥러닝에 보다 익숙해지는 경험이었다.
발표 자료 및 발표를 전담하게됐는데 기술 순위 3위로 끝마친 시점에서 충분히 뒤집기 승산이 있다고 판단했고, 발표 이후 수상 결과 대상(1위)이라는 영예를 안았다. 대회의 핵심 의의에 중점을 둔 점이 차별점을 만들지 않았나 생각한다.

참가 트랙은 A 트랙으로 네트워크 기반 웹 공격 분류로 패턴 기반 매칭 금지, 외부 추가 데이터 금지로 주어진 약 5만개의 페이로드-라벨 셋에서 학습을 진행해야했다.
상당히 적은 데이터라 학습이 잘 될까 싶어 여러 방안에 대해 논의했고, 우선 가장 기본적인 모델들로만 구성해 대회를 진행했다.
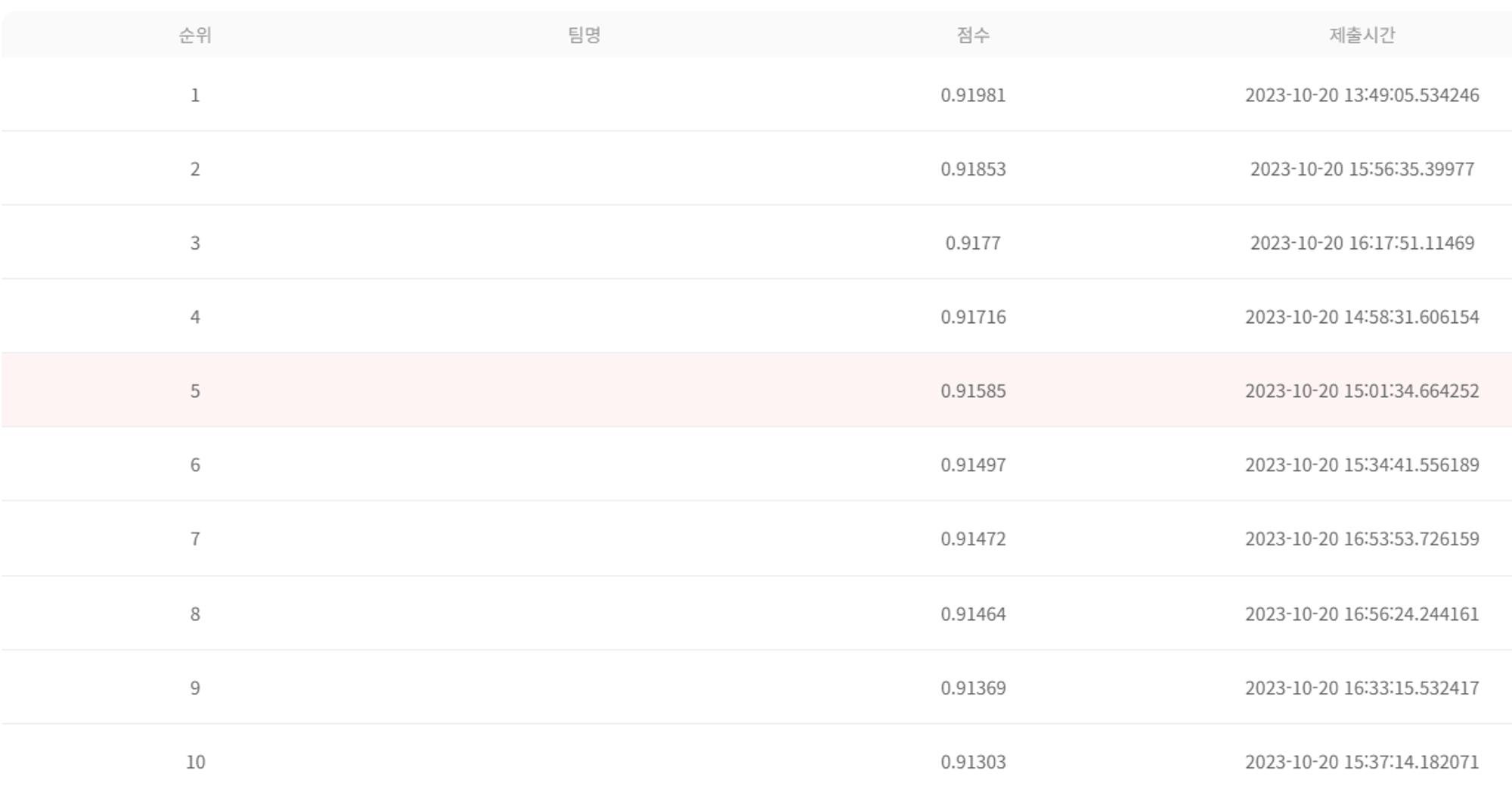
다들 처음에는 나와 똑같이 가볍게 배워보고자 참가한 목적에 비해 의외로 성능이 상당히 좋게 나와 예선을 넘어 본선 7팀에 진출했다. 본선에서는 좀 더 다양한 방식의 모델 강화를 수행했고 생각보다 좋은 분류 성적을 획득했다.
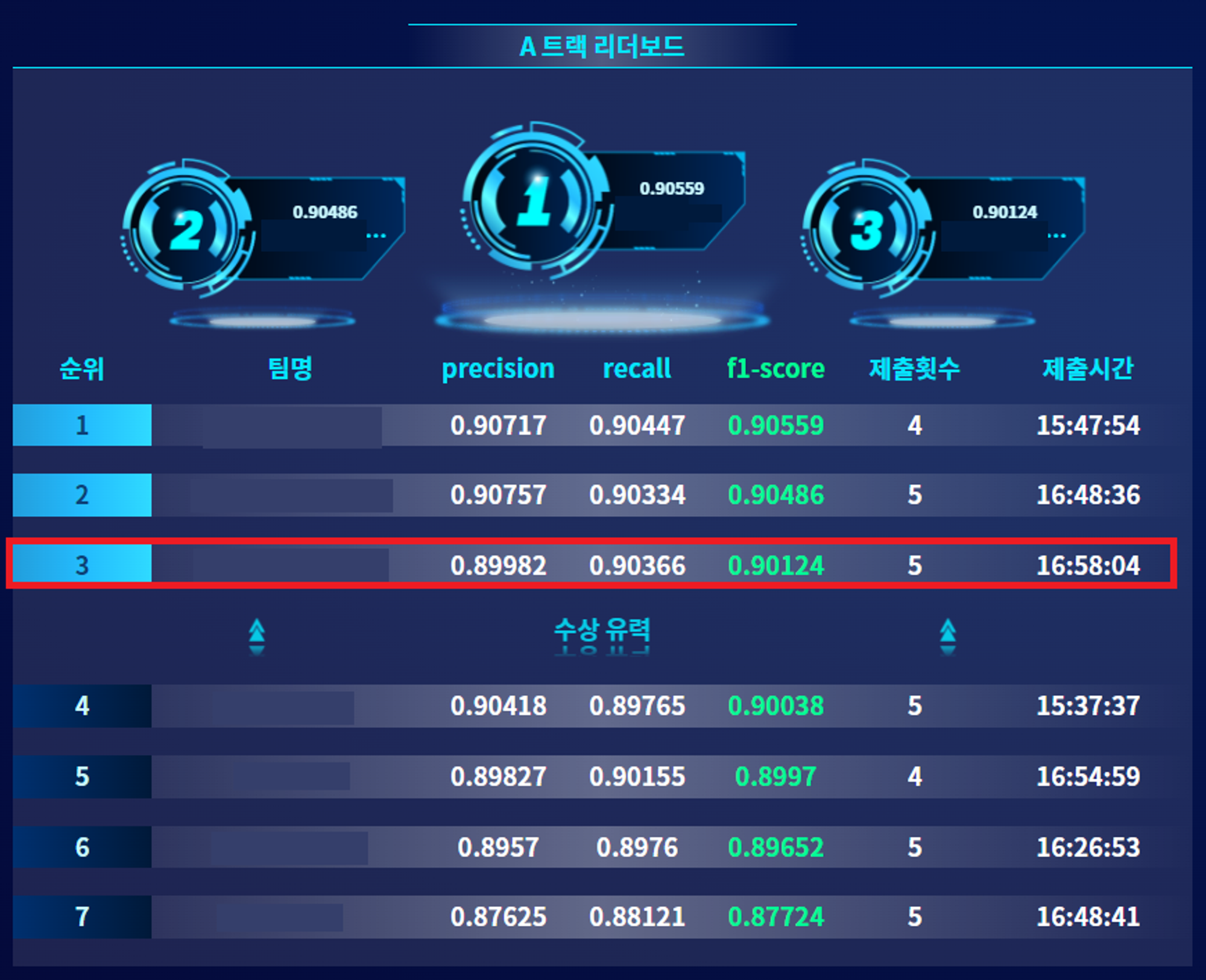
본선부터는 분류 성적 + 발표 평가가 같이 이뤄졌다.
예선때도 모두의 분류 성적 차이가 1% 내외였던만큼 본선에서 큰 이변이 없는한 상위권의 %차이는 적을 것으로 예상했다. (그리고 실제로 1등과 0.5%차이를 넘지 않았다)
결국 발표에서 결과가 갈릴 수 있다고 판단, 본선 막바지부터 발표 및 발표자료를 도맡아 꽤나 힘줘 만들었다. 생각보다 시간이 빠듯해 제출 전날에는 밤을 새 다 만들고 나니 15분 발표 제한시간이 또 걸려 웬만한 대회들보다 발표 연습을 많이 필요로 했다.
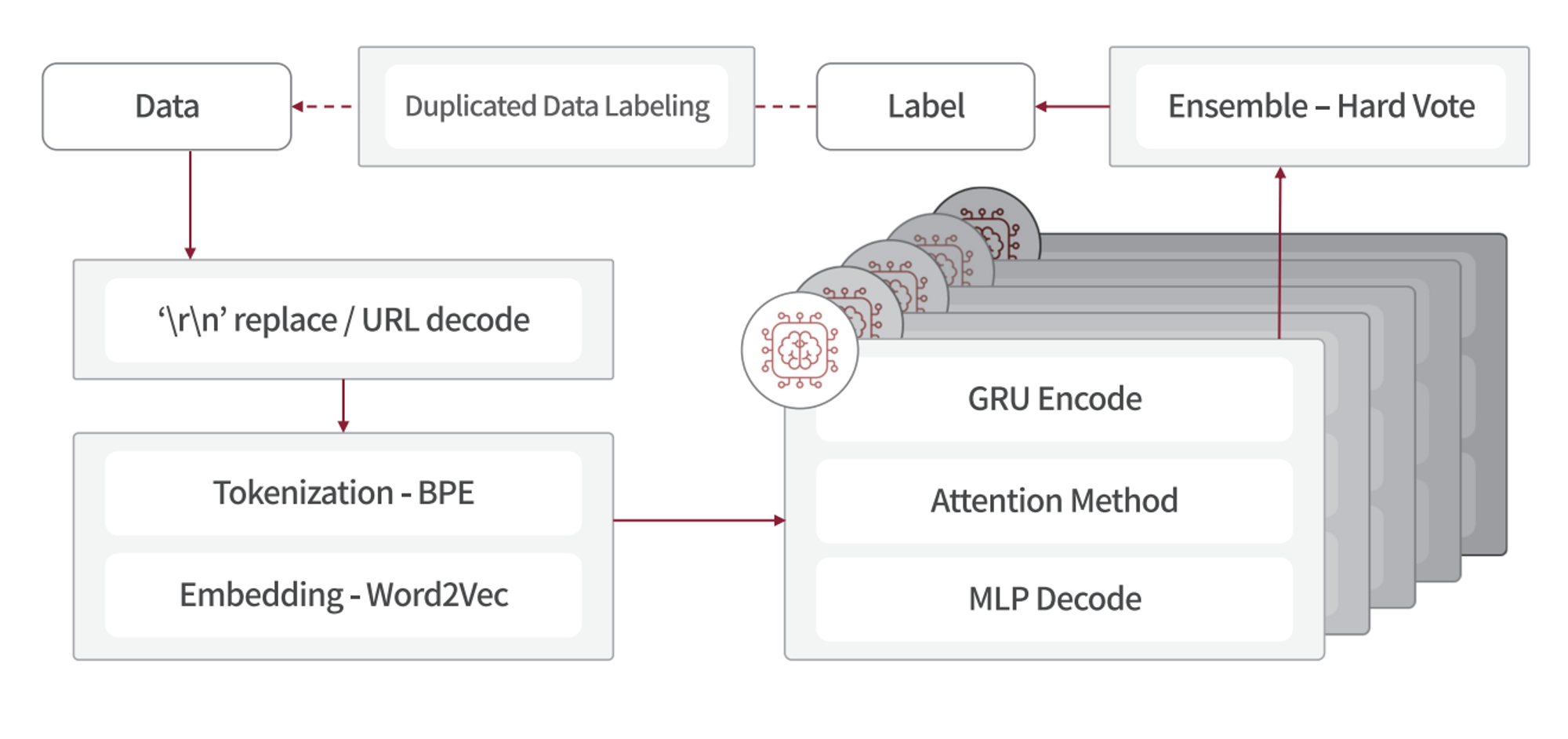
간략한 모델은 위와 같다.
•
데이터 전처리 과정에서 증폭이나 선별, 헤더 제거 등의 별도 처리는 수행하지 않고 의미 전달을 명확하게 하기 위한 간단한 디코딩만 수행
•
OOV문제 최소화를 위한 BPE 토큰화, 분포 가설에 따른 Word2Vec 활용
•
GRU 인코딩 및 장기의존성 문제 해결을 위한 Attention
•
앙상블, LSTM등 여러 신경망 모델의 앙상블도 고려했지만 현 대회 학습셋 결과가 아쉬운 수치에 멈춰 앙상블은 기존 GRU 모델에 랜덤시드만을 다르게 한 5개로 진행
•
언라벨 데이터 라벨링 후 재학습을 통한 일반화 경향 강화
기존에 주어진 학습데이터에 페이로드는 동일한데 라벨이 다른 부분이 있어 이들의 라벨을 제거하고 준지도학습을 수행한 바 있다. 그림에 반영되지 않은 점은 Duplicated Data Labeling → Unlabeled Data Labeling 으로 중복데이터 뿐 아니라 예선 대회에 평가 데이터로 사용된 셋도 학습데이터에 포함시켰다.
대부분 일반적으로 알려진 모델들만을 사용했으며 오히려 요즘 나오는 트랜스포머나 BERT등을 사용하지 않았다는 점에서 아쉬운 평가가 나올 줄 알았으나 발표장에서 오히려 긍정적인 평가를 주셔 감사했다.
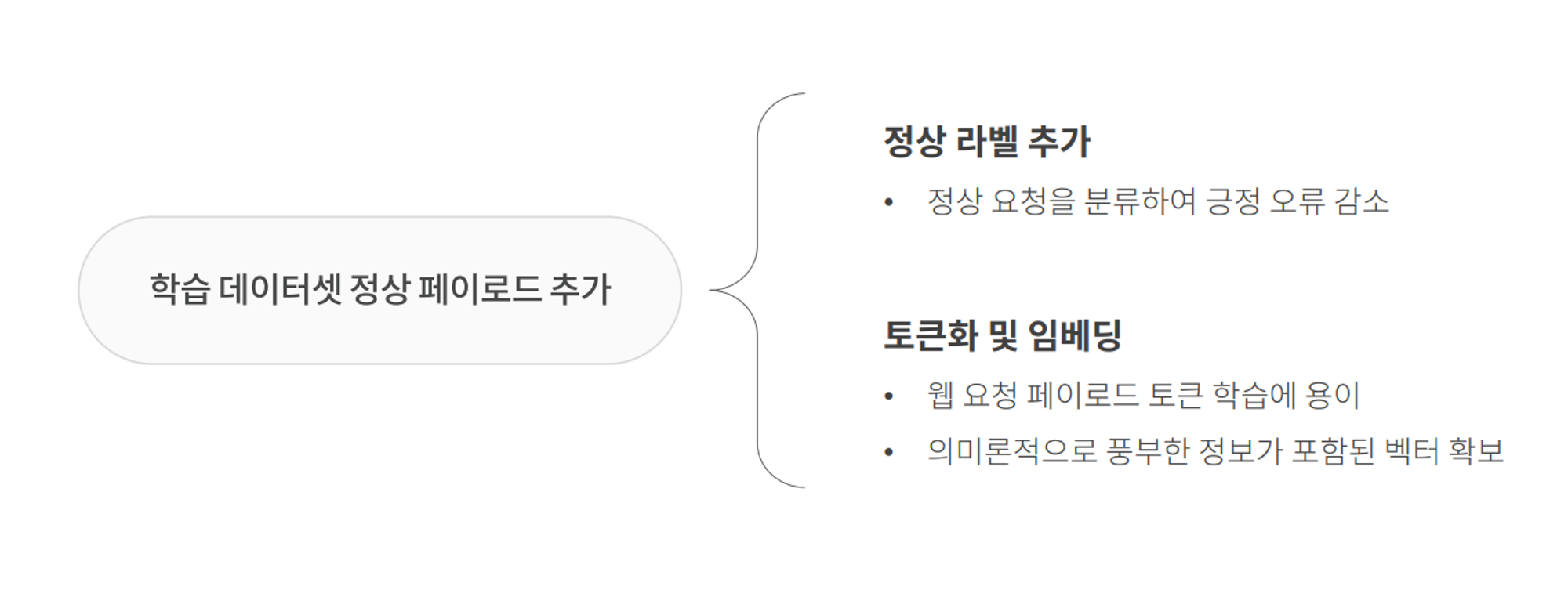

대회 기술보고서에서 필수 작성으로 정해진 부분은 ‘현장적용을 위한 모델 개선방안’이었다.
대회 의의가 단순히 성적 뿐 아니라 실제로 아이디어들을 기반으로 현장에 적용할 수 있냐 없냐가 포인트일거라 가정, 이를 명확히 전달한다면 좋은 인상을 줄 수 있을거라 생각해 해당 부분에 꽤나 힘을 많이 줘 준비했다.
실제로 모델보다 해당 파트에 대해 더 많은 질의응답을 수행했고 어느정도 적절하게 발표 내용 구성을 했다고 사료된다.
아래는 발표 자료 전문이다. (현재 잠금 처리, 관련 문의는 이메일로)